Coding Period: Week 3
Preliminaries
In the last week meeting, we discuss about difficulty to install TensorRT because it close to hardware and requires very specific library/packages to work. The scripts I created for baseline benchmark are useful and will be added to official repository. After using docker for TensorRT, I got a issue on my local machine - docker: Error response from daemon: could not select device driver "" with capabilities: [[gpu]]. I will continue solving this issue. Softwares having strict hardware dependencies are infamous for their difficulty to install in one go. Furthermore, we decide to continue pursue other optimization techniques - Quantization.
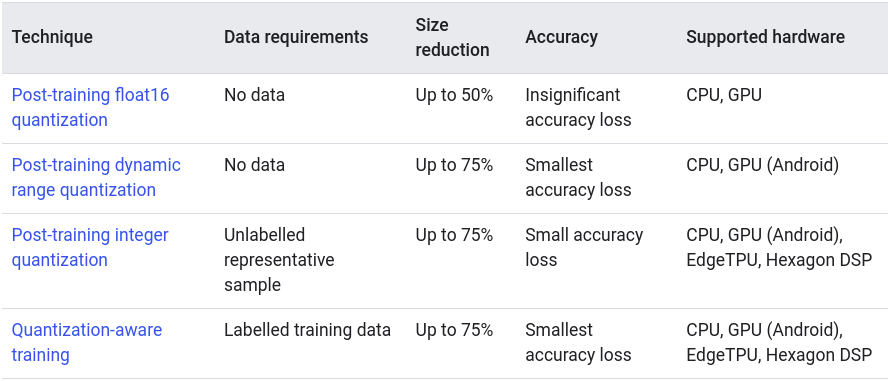
Quantization works by reducing the precision of the numbers used to represent a model’s parameters, which by default are 32-bit floating point numbers. This results in a smaller model size and faster computation. The following table provide overview of quantizations supported by TensorFlow and their effects:
Objectives
- Prepare scripts for baseline evaluation and submit a PR
- Solve TensorRT issues
- Use Post-training quantization techniques to optimize PilotNet
- Dynamic range quantization
- Integer only quantization
- Integer (float fallback) quantization
- Float16 quantization
- Prepare a script to run all optimization techniques and compare.
Additionally completed
- Include Quantization aware training techniques to model optimization stack.
- Include Pruning techniques to model optimization stack.
- Random sparsity pruning
- Combine with post-training quantization
- Random sparsity pruning
Related Issues and Pull requests.
- The code is requested to be add to official repository via PR #67 Add support for baseline evaluation and model optimization
The execution
Tensorflow model Optimization guide provide a good overview of tools to optimize machine learning inference. Currently following techniques are supported:
For this week, I have put additional days to expedite the progress in the project. The GPU server was pre-occupied, so TensorRT usage issues will be address in coming weeks.
Installation of TensorFlow Model Optimization
The instructions are provided [5] as:
# Installing with the `--upgrade` flag ensures you'll get the latest version.
pip install --user --upgrade tensorflow-model-optimization
Post-training quantization
The following table summarizes the choices and the benefits they provide:

-
In dynamic range quantization the weights are quantized post training and the activations are quantized dynamically at inference in this method.
-
Integer quantization is an optimization strategy that converts 32-bit floating-point numbers (such as weights and activation outputs) to the nearest 8-bit fixed-point numbers. This results in a smaller model and increased inferencing speed, which is valuable for low-power devices such as microcontrollers. Using
Integer only quantizationrequires larger RAM size. I kept getting error -W tensorflow/core/framework/cpu_allocator_impl.cc:82] Allocation of 846410400 exceeds 10% of free system memory.on my local machine with 8 GB RAM. So, I used a more powerful machine for this strategy. -
Float16 quantization - TensorFlow Lite now supports converting weights to 16-bit floating point values during model conversion from TensorFlow to TensorFlow Lite’s flat buffer format.
Quantization aware training
This strategy emulates inference-time quantization, creating a model that downstream tools will use to produce actually quantized models. The quantized models use lower-precision (e.g. 8-bit instead of 32-bit float), leading to benefits during deployment.
Weight Pruning
Magnitude-based weight pruning gradually zeroes out model weights during the training process to achieve model sparsity. Sparse models are easier to compress, and we can skip the zeroes during inference for latency improvements. This technique brings improvements via model compression (upto 6x improvement), but till now no latency improvements.
This strategy can also be combined with post-training quantization (applied concurrently) to create a model upto 10x smaller than original. Pruning can be applied to a model together with other model compression techniques for better compression rate. In coming weeks we might explore collaborative optimization technique.
Unstructure pruning
Trim less important parameters irrespective of position, termed as random sparsity in Tensorflow documentation.
Structured pruning
Structural pruning systematically zeroes out model weights at the beginning of the training process. You apply this pruning techniques to regular blocks of weights to speed up inference on supporting HWs, for example: grouping weights in the model by blocks of four and zeroing out two of those weights in each block, known as a 2 by 4 reduction. Compare to the random sparsity, the structured sparsity generally has lower accuracy due to restrictive structure, however, it can reduce inference time significantly on the supported hardware.
Results
| Method | Model size (MB) | MSE | Inference time (s) |
|---|---|---|---|
| PilotNet (original tf format) | 195 | 0.041 | 0.0364 |
| Baseline (tflite format) | 64.9173469543457 | 0.04108056542969754 | 0.007913553237915039 |
| Dynamic Range Q | 16.242530822753906 | 0.04098070281274293 | 0.004902467966079712 |
| Float16 Q | 32.464256286621094 | 0.041072421023905605 | 0.007940708875656129 |
| Q aware training | 16.242530822753906 | 0.04098070281274293 | 0.004691281318664551 |
| Weight pruning | 64.9173469543457 | 0.04257505210072217 | 0.0077278904914855956 |
| Weight pruning + Q | 16.242530822753906 | 0.042606822364652304 | 0.004810283422470093 |
| Integer only Q | 16.244918823242188 | 28157.721509850544 | 0.007908073902130127 |
| Integer (float fallback) Q | 16.244888305664062 | 0.04507085706016211 | 0.00781548523902893 |
All the results are for models converted to tflite models if not specified.
Observations
- The baseline / original model also got improvements in model size (195 -> 64.9 MB) and inference time (0.0364 -> 0.00791) when converted to
tfliteformat without increase in mean square error (MSE). - Quantization aware training strategy gives best model in all aspects -
model size: 4x reduction
MSE: slightly better (0.0001 reduction)
Inference time: ~1.7x reduction- This strategy required access to a subset of training data.
- We also found that integer quantization is not suitable for our model, because we perform a regression task. The precision loss due to quantization severly increase our MSE, making its use impossible.
- From the original model (in tensorflow format), we achieved -
model size: 10x reduction
MSE: slightly better (0.0001 reduction)
Inference time: ~7.7x reduction - The most faster and economical choice would be use Dynamic range quantization because it doesn’t need any dataset or time to train.
Experimental setup
For using the complete dataset, I need a more powerful machine. I used a Nvidia V100 GPU with 32GB memory. The batch size was 1024. All subsets of new datasets are used for experiment.
All the optimized models are publicly available in the google drive.
References
[1] https://github.com/JdeRobot/BehaviorMetrics
[2] https://github.com/JdeRobot/DeepLearningStudio
[3] https://developer.nvidia.com/tensorrt
[4] https://www.tensorflow.org/lite/performance/model_optimization
[5] https://www.tensorflow.org/model_optimization/guide/install
[6] https://docs.nvidia.com/deeplearning/frameworks/tf-trt-user-guide/index.html
[7] https://catalog.ngc.nvidia.com/orgs/nvidia/containers/tensorflow