Coding Period: Week 4
Preliminaries
The previous week, I presented the important theoretical background, implementation, results and observations from optimizating the PilotNet model. In this week, we focus on verifying the utility of the compressed models. We will test the models on different GPU hardward in offline fashion (using usual test scripts) and via simulation with Behavior Metrics tool. It includes enabling inference scripts in Behavior Metrics to utilize the optimized models. If time permits I will continue working on TensorRT and creating optimization script for DeepestLSTMTinyPilotNet architecture.
Objectives
- Evaluation performance of optimized models on another GPU to cross verify the results (offline fashion)
- Check the performance on a test simulation
- Create a script to utilize optimized models in Behavior Metrics
- Benchmark baseline PilotNet modle in terms of
inference time,average speedandposition deviation MAEto complete a lap. - Dynamic range quantized PilotNet model in terms of
inference time,average speedandposition deviation MAEto complete a lap. - Quantized aware trained PilotNet model in terms of
inference time,average speedandposition deviation MAEto complete a lap. - Pruned models in terms of
inference time,average speedandposition deviation MAEto complete a lap. - Compare the simulation results and draw conclusions
- Continue progress on other optimization strategy
Additionally completed
- New issues and solution for execution of TensorFlow supported brain on BehaviorMetrics
Related Issues and Pull requests.
Related to use BehaviorMetrics repository:
- ImportError: cannot import name ‘ft2font’ from ‘matplotlib’ #383
- AttributeError: ‘Brain’ object has no attribute ‘suddenness_distance’ #384
- Skipping registering GPU devices #385
PR to sumbit new script:
The execution
The issue on my local machine mentioned in last week blog - docker: Error response from daemon: could not select device driver "" with capabilities: [[gpu]] was solved by following the recommendation from nvidia forum. The provided server is a docker container and I expect some support from mentor for additional setup because I can not directly use TensorRT docker on another docker container.
All the optimized models are publicly available in the google drive.
Installation of TensorFlow Model Optimization
The instructions are provided [5] as:
# Installing with the `--upgrade` flag ensures you'll get the latest version.
pip install --user --upgrade tensorflow-model-optimization
Verification with other GPU hardware
For cross-verification, I used my personal computer with a NVIDIA GeForce GTX 1050/PCIe/SSE2 GPU with Intel® Core™ i7-7700HQ CPU @ 2.80GHz × 8 CPU, 8 GB RAM and batch size of 1 (for inference) and 64 for loss calculation.
| Method | Model size (MB) | MSE | Inference time (s) |
|---|---|---|---|
| PilotNet (original tf format) | 195 | 0.041 | 0.0364 |
| Baseline | 64.9173469543457 | 0.041032551996720734 | 0.00682752537727356 |
| Dynamic Range Q | 16.242530822753906 | 0.040933178721450386 | 0.004078796863555908 |
| Float16 Q | 32.464256286621094 | 0.041024427111766355 | 0.006837798833847046 |
| Q aware training | 16.242530822753906 | 0.040933178721450386 | 0.004129417657852173 |
| Weight pruning | 64.9173469543457 | 0.04252005337036257 | 0.006857085466384888 |
| Weight pruning + Q | 16.242530822753906 | 0.04255170110407089 | 0.004178661823272705 |
| Integer only Q | 16.244918823242188 | 28147.113743361497 | 0.00712398886680603 |
| Integer (float fallback) Q | 16.244888305664062 | 0.04501058531541387 | 0.007014316082000732 |
All the results are for models converted to tflite models if not specified.
Conclusions
- The improvements are consistent with previous week results - same model compression rate, no increase in MSE and even a little improvement in inference time (better by 0.0009 s).
- The baseline / original model also got improvements in model size (195 -> 64.9 MB) and inference time (0.0364 -> 0.00791) when converted to
tfliteformat without increase in mean square error (MSE). - Dynamic range quantization strategy gives best model in all aspects -
model size: 4x reduction
MSE: slightly better (0.0001 reduction)
Inference time: ~1.7x reduction - Also, the most faster and economical choice would be use Dynamic range quantization because it doesn’t need any dataset or time to train.
- I recommend trying both
Dynamic range quantizationandQuantization aware trainingchose the best because both have competing performance. - We also found that integer quantization is not suitable for our model, because we perform a regression task. The precision loss due to quantization severly increase our MSE, making its use impossible.
- From the original model (in tensorflow format), we achieved -
model size: 10x reduction
MSE: slightly better (0.0001 reduction)
Inference time: ~7.7x reduction
Performance on simulation (online fashion)
I used my personal computer with a NVIDIA GeForce GTX 1050/PCIe/SSE2 GPU with Intel® Core™ i7-7700HQ CPU @ 2.80GHz × 8 CPU, 8 GB RAM and batch size of 1 (for inference). The stats are recorded after approximately one lap in Simple circuit and for comparison, focus should be on the aspect of average calculations. The current BehaviorMetrics tool need more updates for working with a Tensorflow environment and I have tried to provide support by creating and solving issues. Although, I lot of reinstallations and time has been diverted in making environment, cuda, cudnn, VNC and docker work together.
PilotNet (original)

Dynamic range quantization
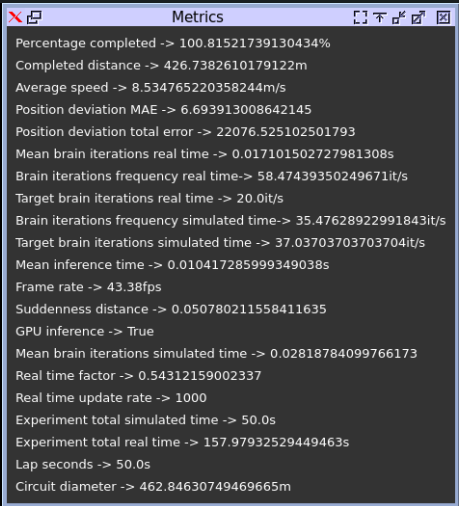
Quantization aware training
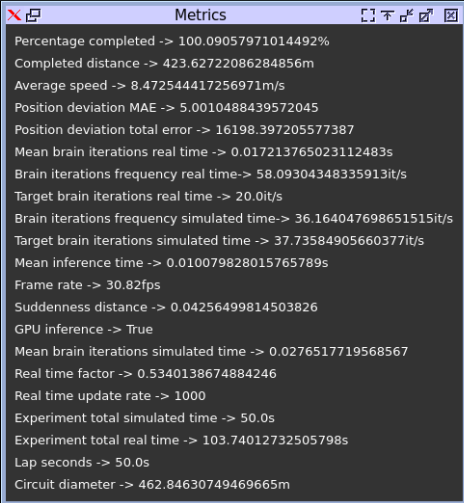
Remaining optimization strategies
Other strategies were not able to complete one lap properly. So, they are excluded from comparison.
Comparison table
| Method | Average speed | Position deviation MAE | Brain iteration frequency (RT) | Mean Inference time (s) |
|---|---|---|---|---|
| PilotNet (original) | 8.386 | 7.406 | 5.585 | 0.124 |
| Dynamic Range Q | 8.534 | 6.693 | 58.474 | 0.010 |
| Q aware training | 8.472 | 5.001 | 58.09 | 0.010 |
Conclusion
- The benefits obtained from optimizing models are relevant for both offline and online (simulation) usecases.
- On average, quantization strategy gives a boost of ~10x times to other aspects (inferece time etc.).
- We observe slight improvement in
Average speedandPosition deviation MAE. The credit can be given to reduced latency by optimized models. - The optimized model complete lap 1 second faster (in 50s) as compare to baseline (in 51s).
- Unfortunately, other strategies such as pruning and integer quantization are not appropriate to be used in simulation.
References
[1] https://github.com/JdeRobot/BehaviorMetrics
[2] https://github.com/JdeRobot/DeepLearningStudio
[3] https://developer.nvidia.com/tensorrt
[4] https://www.tensorflow.org/lite/performance/model_optimization
[5] https://www.tensorflow.org/model_optimization/guide/install
[6] https://docs.nvidia.com/deeplearning/frameworks/tf-trt-user-guide/index.html
[7] https://catalog.ngc.nvidia.com/orgs/nvidia/containers/tensorflow