Coding Period: Week 7
Preliminaries
Last week, we cleared a milestone and cleared GSoC mid-term evaluations for the project! Everyone is happy with results and project pace and I hope to keep things in same momentum. We also uploaded a video explaining the results and progress made so far - Tweet. For this week, I have done performance verification of TensorRT optimized video in online simulation. Further each run was recorded for analyzing and verification. We also target to combine all the results so far and present here in one blog post. Moreover to support TensorRT optimization, the repository codes are updated and PRs are created to include the changes. I also present correction in Quantization aware training optimization and benchmarked the corrected model. Since I use my personal computer for simulation, which has limited space, I explored some memory efficients to run all these experiments. I will also present my founds so others can use it for similar situations.
Objectives
- Complete video demonstration and Mid-term evaluation
- Experiment applying tflite optimization strategy over TensorRT optimized model
- Benchmark TensorRT optimized models via simulation
- Present all the results table in single blog
- Create PRs for includes changes for TensorRT model inference
Additional
- Fix Quantization aware training and benchmark
- Save and share all simulation recording and trained weights online
Related Issues and Pull requests.
Related to use BehaviorMetrics repository:
Related to use DeepLearningStudio repository:
- Add support for inference optimization with TensorRT for Tensorflow models #71
- QAT correction in latest commit - Add support for baseline evaluation and model optimization #67
Important links
- BehaviorMetrics simulations - https://drive.google.com/drive/folders/1ovjuWjSy-ea7YtgnaSsgVsHnbo0HJY1A?usp=sharing
- Trained weights - https://drive.google.com/drive/folders/1j2nnmfvRdQF5Ypfv1p3QF2p2dpNbXzkt?usp=sharing
The execution
Applying tflite optimization strategies over TensorRT optimized model
Unfortunately, I observed no change from the typical performance of the tflite optimization strategy. After applying them, the size of the models was reduced as expected, but the performance boost was also gone. We can conclude that for our current PilotNet architecture, the chances of TensorRT are not utilized by tflite optimization strategies, therefore there is no benefit in applying them consequently.
Benchmark TensorRT optimized model via Simulation
I used my personal computer with a 4 GB NVIDIA GeForce GTX 1050/PCIe/SSE2 GPU and batch size of 1 (for inference) on SimpleCircuit. Initially I had the idea that TensorRT needs to be installed in BehaviorMetric environment also to utilize them. However I had every less memory remaining on my computer to use 2 conda environments, store trained models and use docker container. So, I tried some methods to reduce the memory needs - Mount volumes into a running container and https://blog.adriel.co.nz/2018/01/25/change-docker-data-directory-in-debian-jessie/. I also encountered an issue - Tensorflow 2.4.1 hangs on any operation using Conda which was actually related to albumentations package and needs re-installation. All these failed attempts took me more than half a day, but I learned a lot during it. Fortunately, at the end I figure out that we can directly utilize TensorRT optimized models.
PilotNet (baseline)
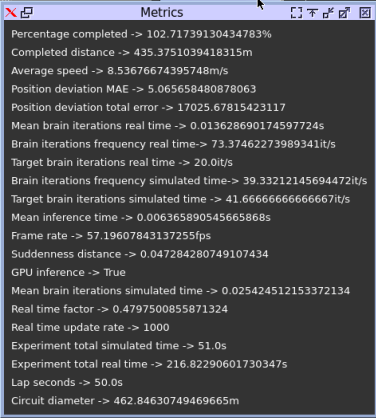
TF-TRT (Precision = Float32)
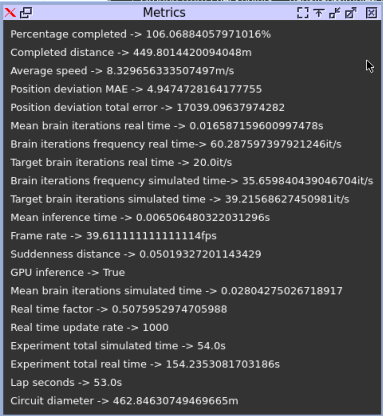
TF-TRT (Precision = Float16)
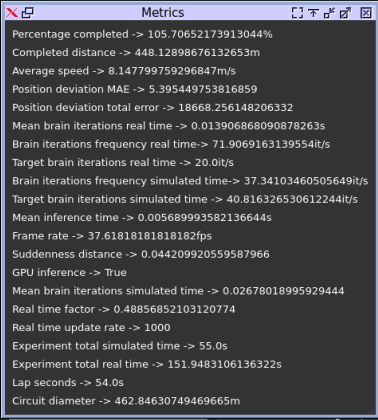
TF-TRT (Precision = Int8)
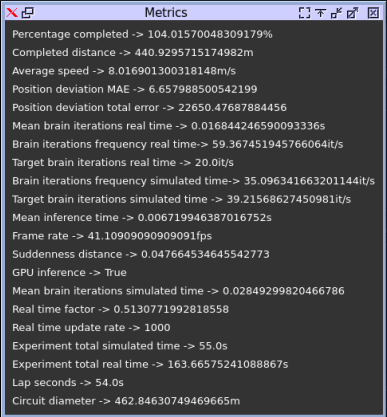
We can observe that the performance is better than all previous optimization methods. The quantitative results are presented together with other experimental resutls. All the simulation videos are share in the link presented above.
Quantization Aware Training correction and benchmarking
Simulation
The correction is included in the PR#67. The simulation results are as follow:
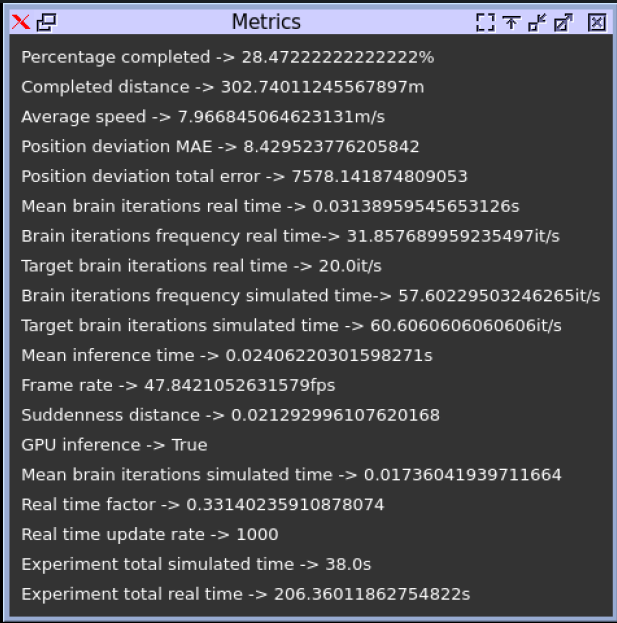
Offline evaluation
The offline results are:
| Method | Model size (MB) | MSE | Inference time (s) |
|---|---|---|---|
| Baseline | 64.9173469543457 | 0.04108056542590139 | 0.01011916732788086 |
| Q aware training | 16.250564575195312 | 0.042138221871067326 | 0.009550530910491944 |
This can not be directly compared to other results because the performance depends a lot on hardware load and specifications, but we can compare to baseline. There is a slight improvement.
Combined result table - Simulation
All the simulations are conducted on a 4 GB NVIDIA GeForce GTX 1050/PCIe/SSE2 GPU and batch size of 1 on SimpleCircuit. Only models which have completed one lap are presented here.
| Method | Average speed | Position deviation MAE | Brain iteration frequency (RT) | Mean Inference time (s) | Real time factor |
|---|---|---|---|---|---|
| PilotNet (original) | 8.386 | 7.406 | 5.585 | 0.124 | 0.557 |
| Dynamic Range Q | 8.534 | 6.693 | 58.474 | 0.010 | 0.54 |
| TF-TRT Baseline | 8.536 | 5.06 | 73.37 | 0.0063 | 0.47 |
| TF-TRT FP32 | 8.32 | 4.94 | 60.28 | 0.0065 | 0.50 |
| TF-TRT FP16 | 8.14 | 5.39 | 71.90 | 0.0056 | 0.48 |
| TF-TRT Int8 | 8.01 | 6.65 | 59.36 | 0.0067 | 0.51 |
Combined result table - Offline scripting
All the simulations are conducted on a Nvidia V100 GPU with 32GB memory. The batch size was 1024. All subsets of new datasets are used for experiment, testset - SimpleCircuit, Montreal and Montemelo circuits.
| Method | Model size (MB) | MSE | Inference time (s) |
|---|---|---|---|
| PilotNet (original tf format) | 195 | 0.041 | 0.0364 |
| Baseline (tflite format) | 64.9173469543457 | 0.04108056542969754 | 0.007913553237915039 |
| Dynamic Range Q | 16.242530822753906 | 0.04098070281274293 | 0.004902467966079712 |
| Float16 Q | 32.464256286621094 | 0.041072421023905605 | 0.007940708875656129 |
| Weight pruning | 64.9173469543457 | 0.04257505210072217 | 0.0077278904914855956 |
| Weight pruning + Q | 16.242530822753906 | 0.042606822364652304 | 0.004810283422470093 |
| Integer only Q | 16.244918823242188 | 28157.721509850544 | 0.007908073902130127 |
| Integer (float fallback) Q | 16.244888305664062 | 0.04507085706016211 | 0.00781548523902893 |
| Method | Model size (MB) | MSE | Inference time (s) |
|---|---|---|---|
| PilotNet (original tf format) | 195 | 0.041 | 0.0364 |
| Baseline (tflite format) | 64.9173469543457 | 0.04108056542969754 | 0.007913553237915039 |
| CQAT | 16.250564575195312 | 0.0393811650675438 | 0.007680371761322021 |
| PQAT | 16.250564575195312 | 0.043669467093106665 | 0.007949142932891846 |
| PCQAT | 16.250564575195312 | 0.039242053481006144 | 0.007946955680847167 |
Here, I used the server with a 8 GB NVIDIA GeForce GTX 1080/PCIe/SSE2 GPU and batch size of 128 (for inference).
| Method | Model size (MB) | MSE | Inference time (s) |
|---|---|---|---|
| Baseline | 195 | 0.041032556329194385 | 0.0012623071670532227 |
| Precision fp32 | 260 | 0.04103255125749467 | 0.0013057808876037597 |
| Precision fp16 | 260 | 0.04103255125749467 | 0.0021804444789886475 |
| Precision int8 | 260 | 0.04103255125749467 | 0.0011799652576446533 |
Summarizing the improvements
- We achieved a ~12x reduction in the model memory size with
Dynamic range quantization. - We maintain a similar
MSEvalue (at best 0.001 better) as baseline in offline evaluation. - We achieved a ~33x better inference time with
TensorRT Int8optimization and ~7.5x better inference time withDynamic range quantizationin offline evaluation. - We achieved ~0.66x times smaller
Position deviation MAEand ~12x time higher Brain iteration frequency (RT) in simulation. - We achieved ~22x time improvement in
Mean inference timein simulation.
Recommendations
- Tflite optimized models gives better performance than original models with very less memory size. The installation is easy and there is no specific hardware constraints. I would recommend
Dynamic range quantizationas first optimization method. - TensorRT optimized models have best performance in both offline and simulation. However, they have large memory footprint. If the disk space is not a constraint, I would recommend using
Int8orFloat16precision model.
References
[1] https://github.com/JdeRobot/BehaviorMetrics
[2] https://github.com/JdeRobot/DeepLearningStudio
[3] https://developer.nvidia.com/tensorrt
[4] https://www.tensorflow.org/lite/performance/model_optimization
[5] https://www.tensorflow.org/model_optimization/guide/install
[6] https://docs.nvidia.com/deeplearning/frameworks/tf-trt-user-guide/index.html
[7] https://catalog.ngc.nvidia.com/orgs/nvidia/containers/tensorflow
[8] https://www.tensorflow.org/model_optimization/guide