Week 5: June 26 ~ July 02
Preliminaries
Our current model employs an embedding layer to process the high-level commands, which are then concatenated with the flattened visual features. However, given that we only have four discrete high-level commands, the use of an embedding layer might be overcomplicated for our scenario. Therefore, we plan to experiment with one-hot encoding for these high-level commands this week.
Until now, our model has ignored traffic lights as the expert agent was configured to do so during data collection. However, we believe incorporating traffic light status as an additional input to our model would make our agent more compliant with real-world traffic regulations.
With the approaching midterm evaluation and the significant progress we’ve made so far, we are also considering creating a demo video of our work. We aim to showcase our advancements on our Youtube Channel. Moreover, we plan to update our code repository and compose a comprehensive README to provide better guidance for those interested in our project. and write a README.
Objectives
- Replace the embedding layer for high-level commands with one-hot encoding
- Introduce traffic light status as an additional input to the model
- Write a README for repository
- Produce a demo video for the JdeRobot Youtube Channel
Execution
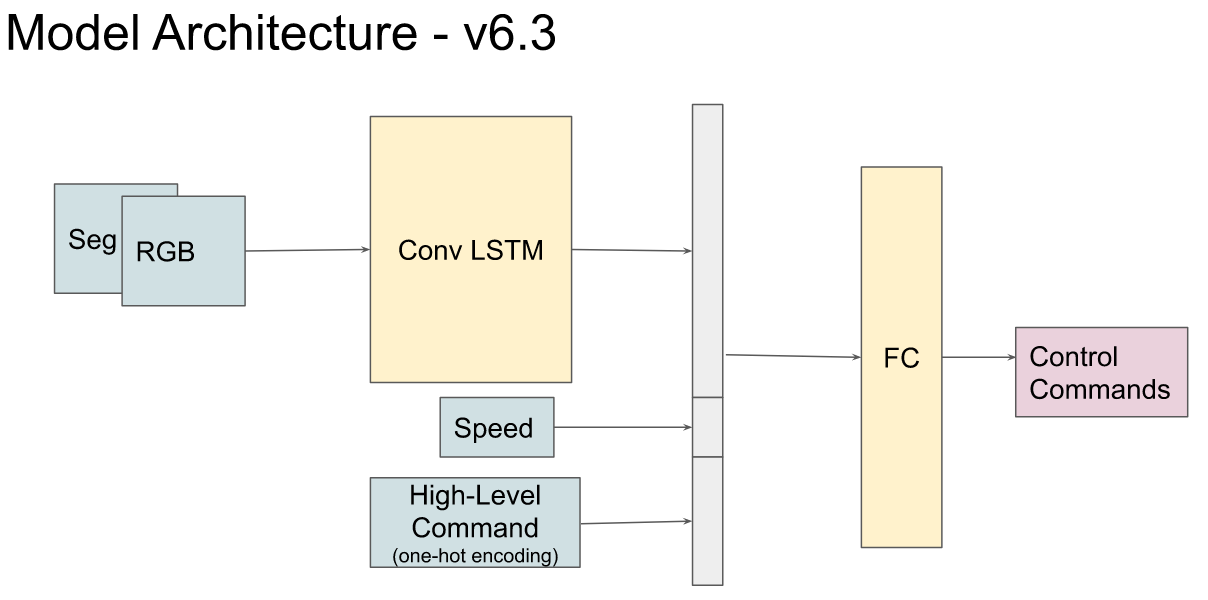
One-Hot Encoding for High-Level Command
Below is the diagram illustrating the revised model architecture which now processes high-level commands using one-hot encoding. Surprisingly, this adjustment seems to have negatively impacted the model’s performance. The agent now occasionally collides with static objects while executing a turn. This suggests that the agent, using the one-hot encoded commands, hasn’t learned the task of making turns as effectively as it did when the embedding layer was used. This result is counterintuitive, given that one-hot encoding generally presents simpler, more explicit information for the model to learn, thus eliminating the need for the model to learn the weights for an embedding layer.
Transition to CARLA 0.9.14
This week, we also initiated the transition from CARLA 0.9.13 to 0.9.14. The main motivations for this change were as follows:
- In CARLA 0.9.14, we can set the target speed of an autopilot agent via the Traffic Manager, thus allowing us to maintain a constant speed for the expert agent.
- CARLA 0.9.14 allows for differentiation between various types of vehicles through semantic segmentation.
- In the latest version, we can retrieve the traffic light status for each frame.
However, this transition wasn’t entirely smooth. An issue we ran into was that CARLA updated its semantic segmentation labels in version 0.9.14 to align with the Cityscape dataset. Consequently, our older models, for which data was collected from version 0.9.13, can no longer be used for evaluation moving forward.
Traffic Light Status As Model Input
The image below illustrates the architecture where we’ve added traffic light status as an additional input modality. The status of the traffic light can take one of four discrete values, encoded using one-hot encoding:
- 0 Not at traffic light
- 1 Red
- 2 Green
- 3 Yellow

As can be seen in the video below, the model learns to stop at traffic lights. Please note that the video demonstrates successful cases primarily. The overall performance of the model, however, is not yet optimal, as it frequently runs red lights. We will continuously workto improve this aspect and to make our model more accurate in responding to traffic signals.
Enjoy Reading This Article?
Here are some more articles you might like to read next: