Week 9: July 24 ~ July 30
Preliminaries
This week, our focus was on enhancing the performance of the model, particularly in addressing a prevalent issue identified in the previous week: the model would suddenly halt and become stuck in a state, especially when it is crossing an intersection. We tackled this problem using two main approaches:
- Finetuning the model with more junction data.
- Use DAgger (Data Aggregation) to iteratively improve the model.
In addition, we faced a problem with our current evaluation metrics: they do not detect whether the model is correctly following turning instructions. During an evaluation episode, if the vehicle makes a wrong turn, calculating the percentage of the route completed becomes meaningless since it deviates from the intended route. Thus, it’s necessary to implement a mechanism to detect which turn the vehicle actually made. This way, we can terminate the testing episode if an incorrect turn is made and proceed to the next one.
Objectives
- Refine the evaluation metrics
- Continue improving model (finetuning, DAgger)
- Finish setting up Behavior Metrics
Execution
Current Models
This week we trained and compared three models:
- v8.0: vanilla model trained on 80 episodes of training data
- v8.1: v8.0 finetuned on 80 additional junction data episodes
- v8.2: v8.0 retrained with DAgger for 3 iterations
Baseline - v8.0
In the video below, the agent is able to roam the streets without suddenly stopping. However, we can still observe several problems. (1) It fails to make a left turn at around 00:40. (2) Starting from 1:15, the agent drifts to the left lane, potentially causing a collision if there were other vehicles around.
(Modified) DAgger Implementation
One of the challenges this week was to implement DAgger. As previously described, DAgger involves running the trained agent in the simulator, with the expert on the side. This allows the expert to demonstrate in more diverse scenearios that the agent might realistically encounter. While the agent drives the car, we record the actions the expert would have taken for each state and add this extra data to our dataset to retrain the model. However, using the CARLA traffic manager as the expert presents a challenge, as there is no way to “query” the expert while allowing the agent to drive the vehicle. To address this, we implemented DAgger in the following way:
- Train an agent using the initial dataset.
- Allow both the agent and the expert to drive the car in the simulator, alternating every 20 frames.
- Only record the actions taken by the expert, not the agent.
- Incorporate the new data into the training set and retrain the agent.
- Repeat Process, iteratively refining the agent’s performance.
The image below demonstrates a contrasting situation where the expert and the model choose different actions during DAgger data collection. In this specific scenario, the agent (model) opts to accelerate, likely because the traffic light is green. Meanwhile, the expert seizes the opportunity to demonstrate the “correct” action by applying the brake, recognizing the presence of another vehicle ahead. This example highlights the valuable corrections that the expert can provide in the DAgger process, guiding the model towards more sophisticated decision-making in complex scenarios.
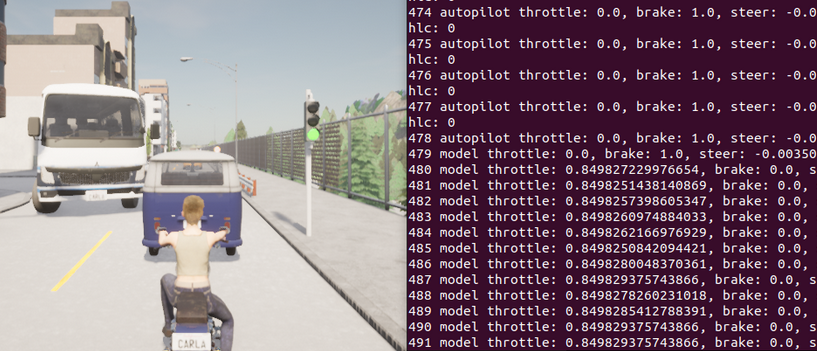
Turning Detection
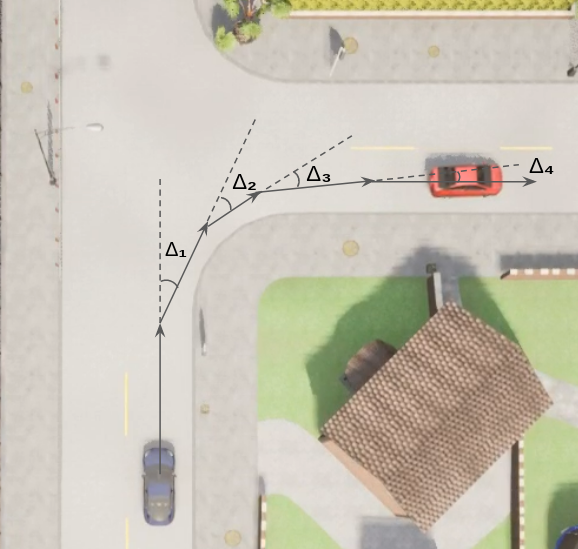
During evaluation, the model is tested on a set of routes with predefined starting and target locations, as well as a sequence of turning instructions. In order to better evaluate the model, we developed a mechanism to accumulately calculate the angle turned at a junction, as shown in the picture below. The idea is to record the changes in the yaw of the vehicle upon entering a junction. When the evluation program detects a failed or wrong turn, the episode ends and the testing moves on to the next one.
Demo 8.2.2
The video below demonstrates the model refined by DAgger for three times. For testing its ability to follow the lane and navigate intersections, no obstacles are spawned and the traffic lights are set to green.
Enjoy Reading This Article?
Here are some more articles you might like to read next: