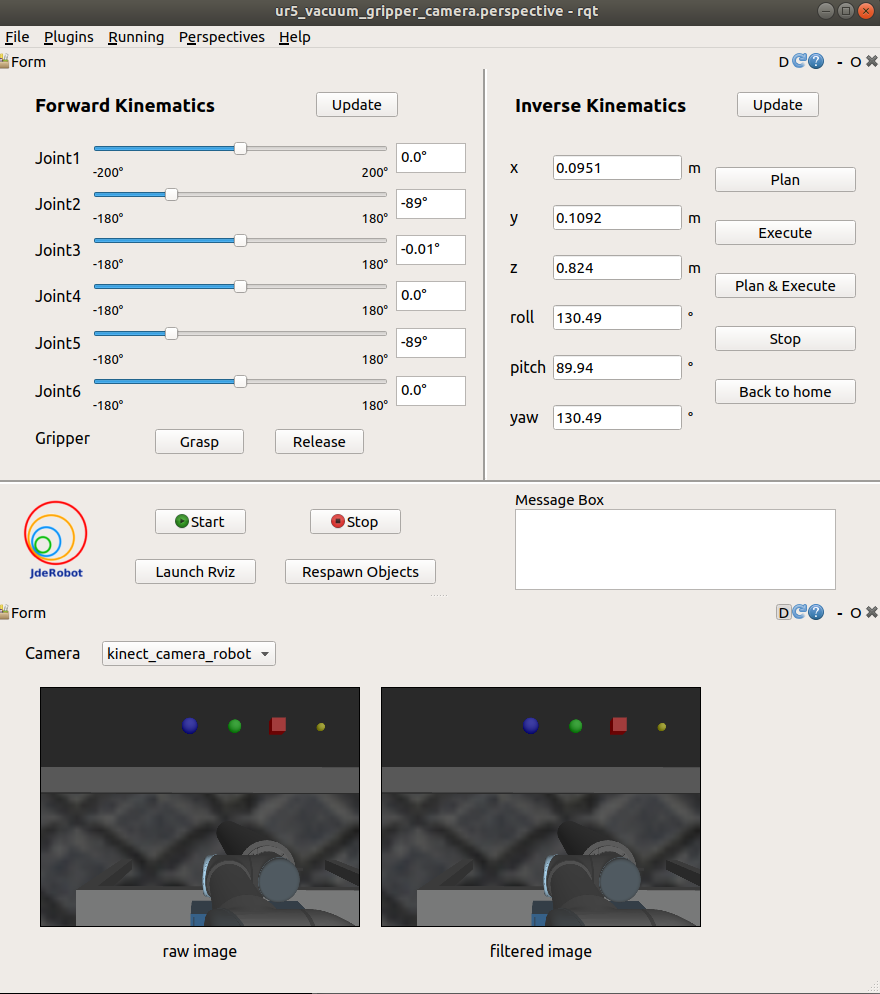
GUI for the second exercise
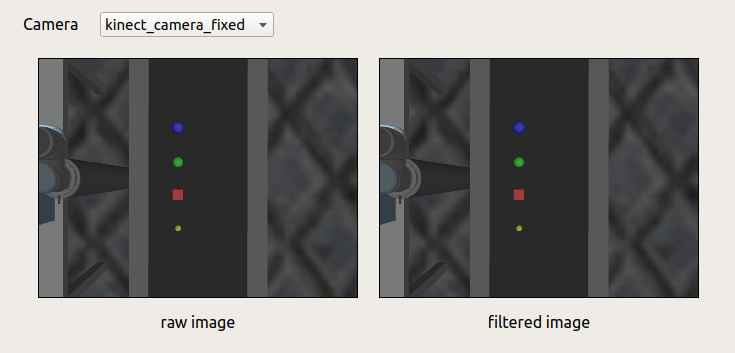
Two new plugins, rqt_vaccum_gripper and rqt_camera, are implemented for the second exercise. The rqt_vaccum_gripper plugin is based on the rqt_kinetic plugin. The slider for gripper joint is changed into grasp and release button because we will use vacuum gripper in the second exercise. The rqt_camera plugin subscribes to and shows rgb raw image and filtered image with camera namespace that can be chosen with the combo box.
pick and place with vacuum gripper
There are currently two problems with the vacuum gripper. The first one is that the same warning and error messages keep spawning with the previous demo. I spent plenty of time trying to solve it, but any other method that can remove the error messages will also make the vaccum gripper not working.
[ERROR] [1595222494.314720502, 2495.925000000]: Transform error: "vacuum_gripper2" passed to lookupTransform argument source_frame does not exist.
[ERROR] [1595222494.314789680, 2495.925000000]: Transform cache was not updated. Self-filtering may fail.
[ WARN] [1595222494.391687458, 2495.997000000]: The complete state of the robot is not yet known. Missing gripper_joint, gripper_joint1, gripper_joint2, gripper_joint3, gripper_joint4, gripper_joint5, gripper_joint6, gripper_joint7, gripper_joint8
The second one is that we cannot use the pick method in exercise one because there is no joint that can move to grasp the object. Therefore, we cannot add objects into planning scene because they will be seen as obstacles. How to separate objects and obstacles is also a essential problem need to be solved.
Obstacle Detection
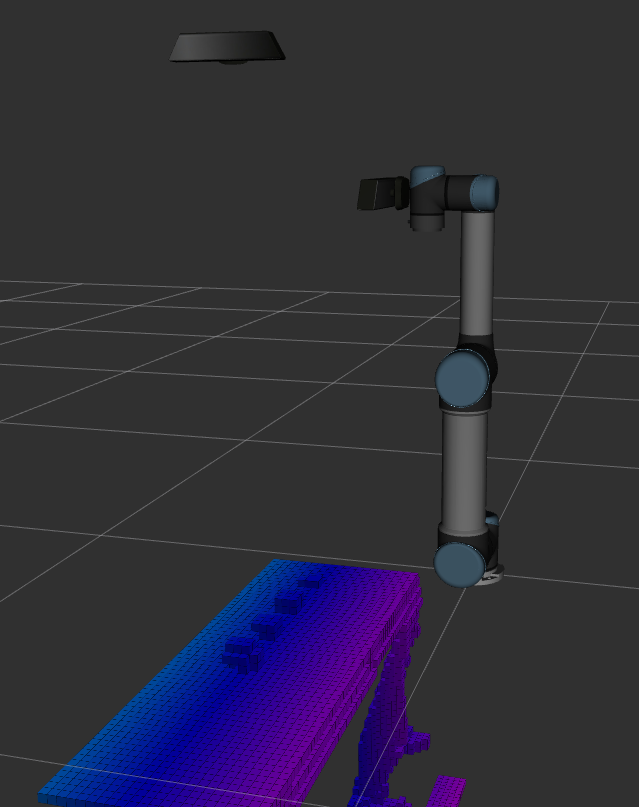
With ocotomap server and depth point cloud input, octomap message can be published and visulized in Rviz as image below. When resolution is 0.1m, we even cannot tell where the objects are because their size are less than 0.1m. When resolution is 0.02m, the update rate becomes very slow. It takes about three to four seconds to publish a new octomap message. When resolution is 0.05m, we can separate object and conveyor, and update rate is about 1.7hz. However, it still takes several seconds to fully update the map when the camera moves or the scene changes. Therefore, if we want to use vision-based obstacle detection method, it would be better to use the point cloud from a fixed camera which can see the whole scene.
Resolution = 0.1m
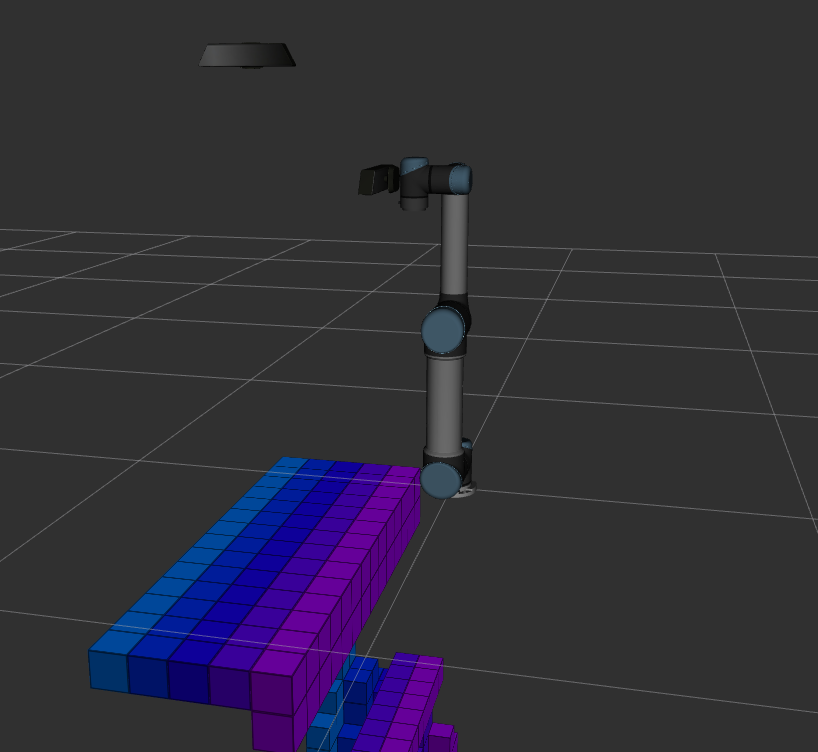
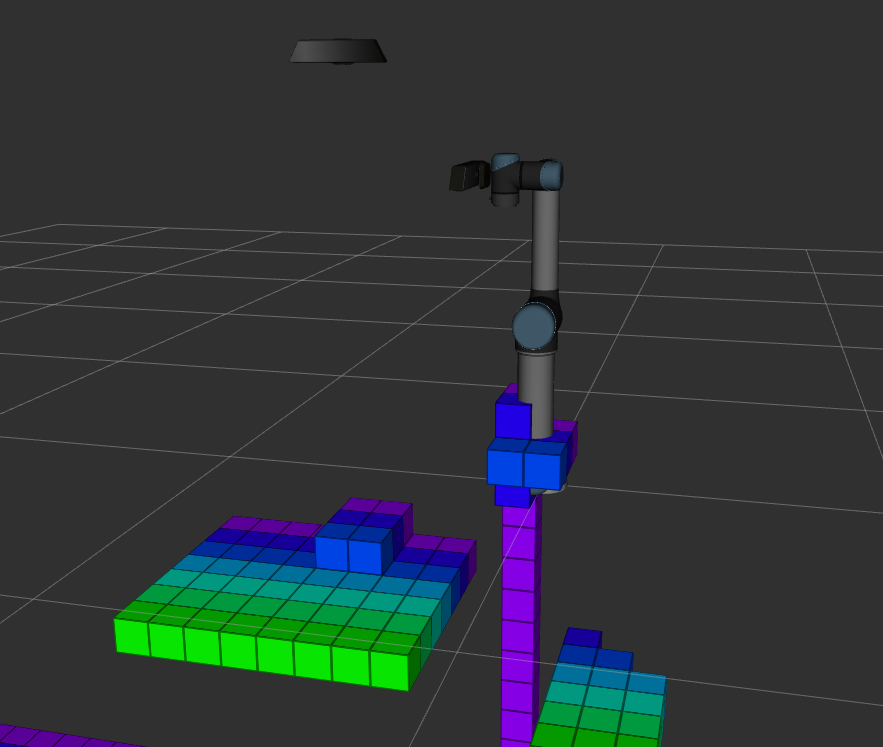
Resolution = 0.05m
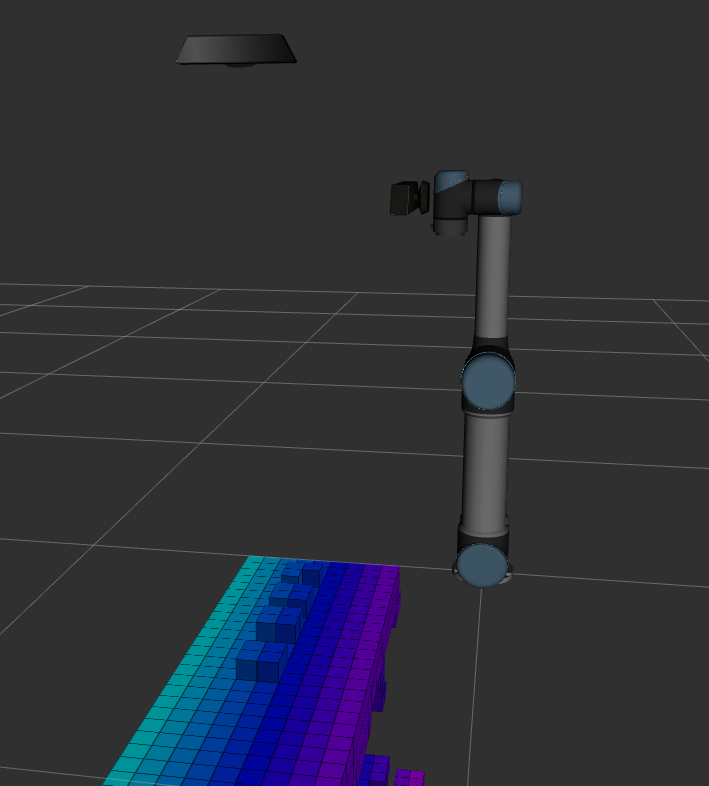
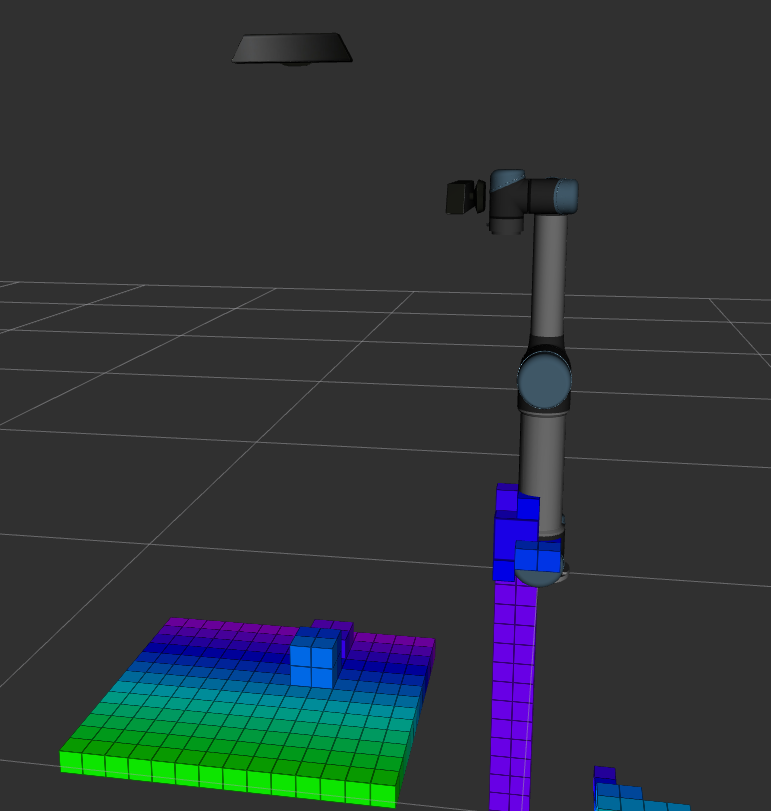
Resolution = 0.02m
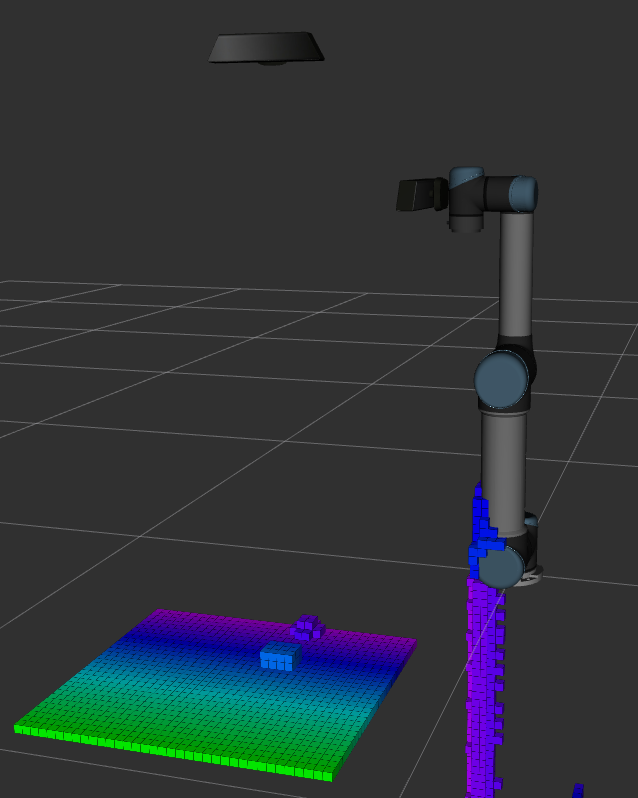
Object Detection
With OpenCV, I can detect the object based on their shape and color, but I still need to use the height and size position of the objects to calculate the position, but the solution with point cloud should be able to finished in one or two days. The image below is the point cloud from both the kinect in robot and the fixed kinect.
Add API to grasp object without tuning gripper width(exercise one)
It is finished with a map between object width and gripper joint value. When object name is given, gripper orientation is perfectly vertical or horizontal, gripper joint value can be internally set for the user. The documentation is updated.